
Ce billet reprend une partie de l’étude sur le fichage politique, axée sur le rôle d’un des laboratoires du CNRS, pour une meilleure visibilité (inutile de le relire si vous avez déjà lu l’étude sur le fichage politique de jeudi). Contacté par nos soins, ni lui ni le CNRS ne nous a répondu…
- Que prévoient les conditions d’utilisation Twitter ?
- Un laboratoire du CNRS aurait aussi fiché les opinions politiques de près de 200 000 personnes !
- Réglementation et Discussion
- Plainte
I. Visibrain, ou Big Brother à la maison
Eu DisinfoLab a utilisé un outil très puissant (et coûteux) permettant d’analyser Twitter – il s’agit ici du logiciel Visibrain , qui sert normalement à des analyses marketing pour les grandes entreprises :

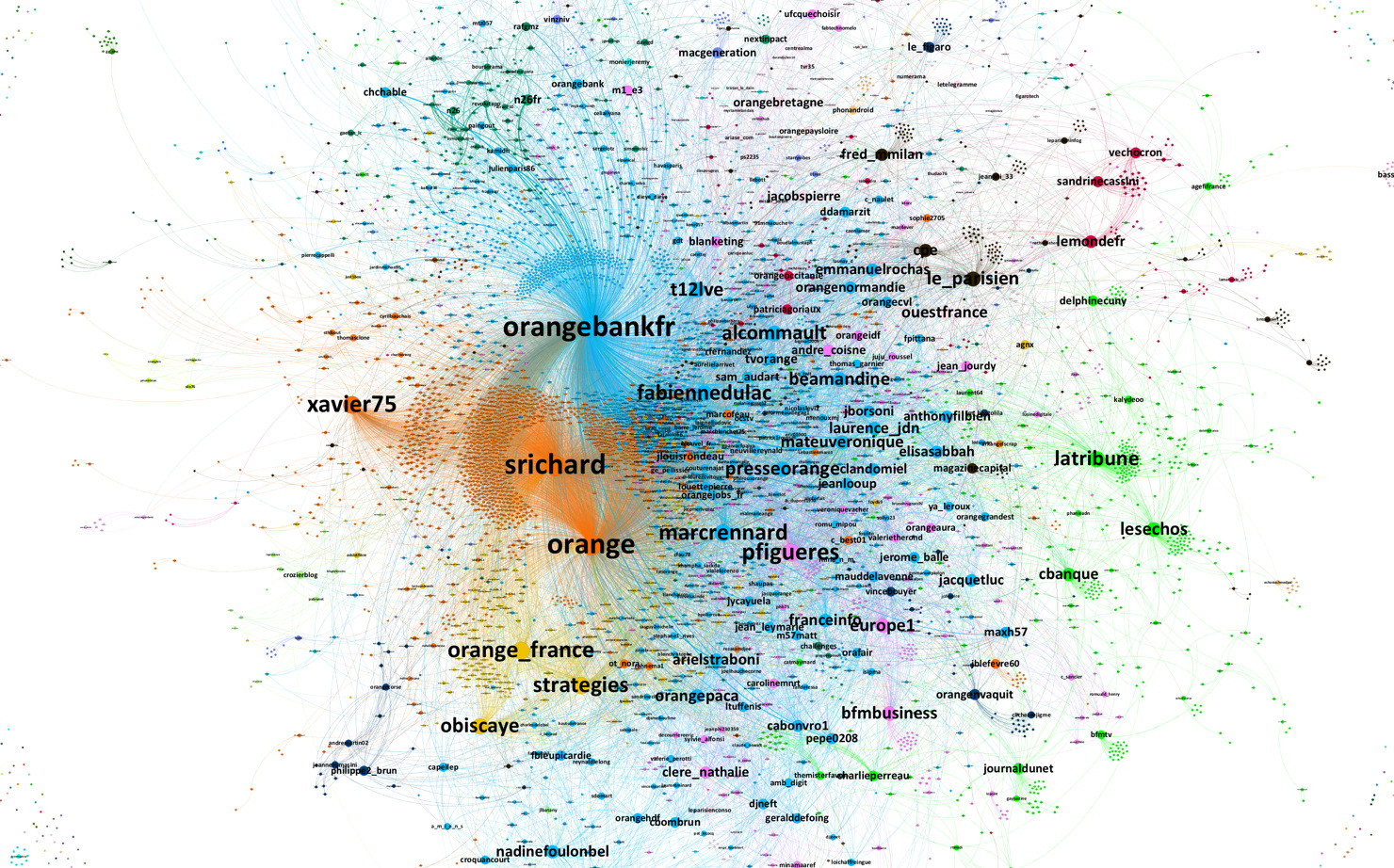
L’essentiel est dans le graphique précédent. Si vous voulez en savoir plus sur ce logiciel, vous pouvez dérouler ici une analyse détaillée : (elle est affichée par défaut)
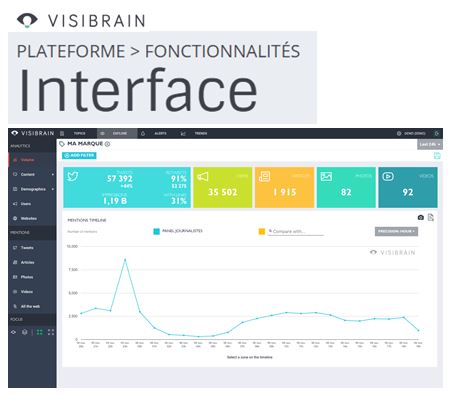
et permet de réaliser en fait automatiquement les graphiques que présente Nicolas Vanderniest :

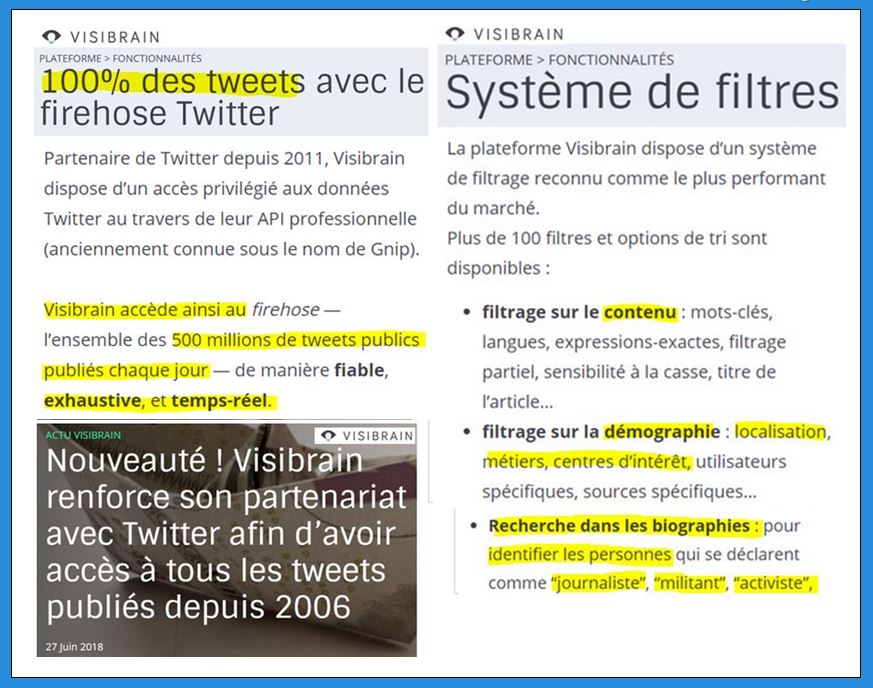
En fait, ce logiciel (dont nous allons détailler les caractéristiques, car c’est très important) donne accès… à tous les tweets de Twitter, en temps réel (sources : 1, 2, 3) :



On peut largement filtrer, en particulier par “métiers et centres d’intérêts” (source) :

On compte explicitement dans les Métiers “journaliste” ou… “militants politiques” (source) :

Ah, quel est le métier le plus visé… ?
De même pour les centres d’intérêts (source) :

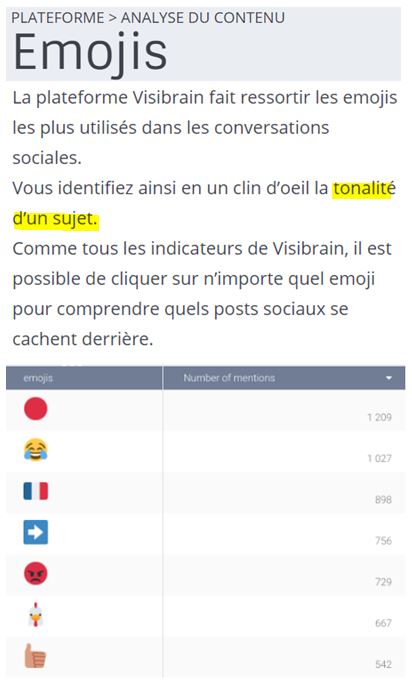
Comme on n’arrête pas le progrès, on peut même analyser les émojis (source) :
On peut aussi chercher dans les biographies – en particulier pour trouver les “journalistes, militants et activistes” (source) :

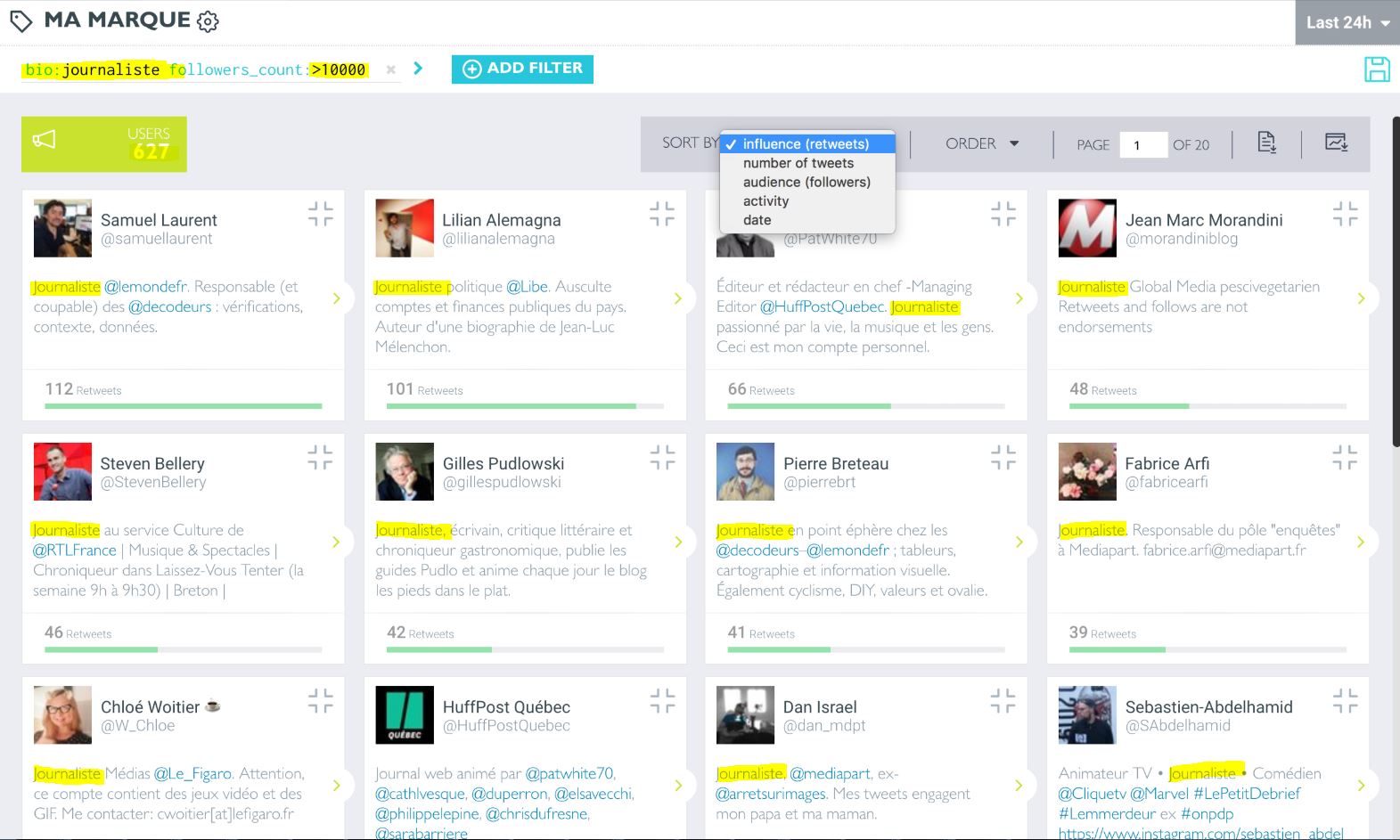
Oh des journalistes avec plus de 10 000 abonnés…
On pourra alors en faire des panels pour les suivre de très près (source) :
De même, le logiciel déterminera généralement votre localisation et votre genre (sources : 1 et 2) :


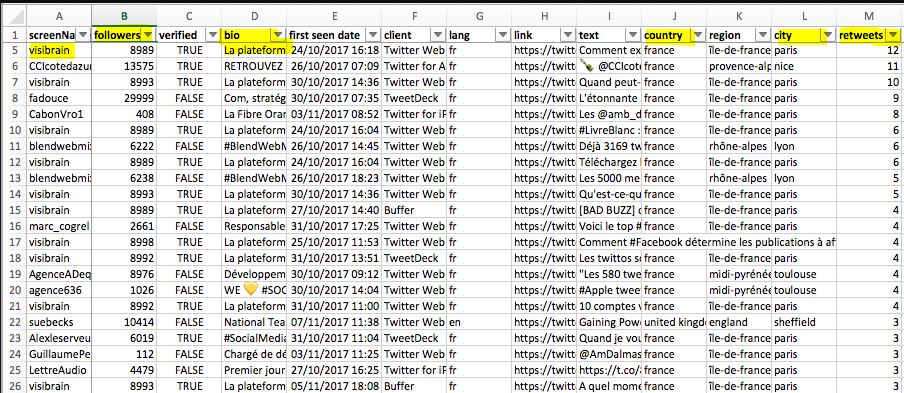
Ce logiciel Big Brother vous facilite la vie en vous permettant d’exporter toutes les données qui vous intéressent sous Excel (source) :

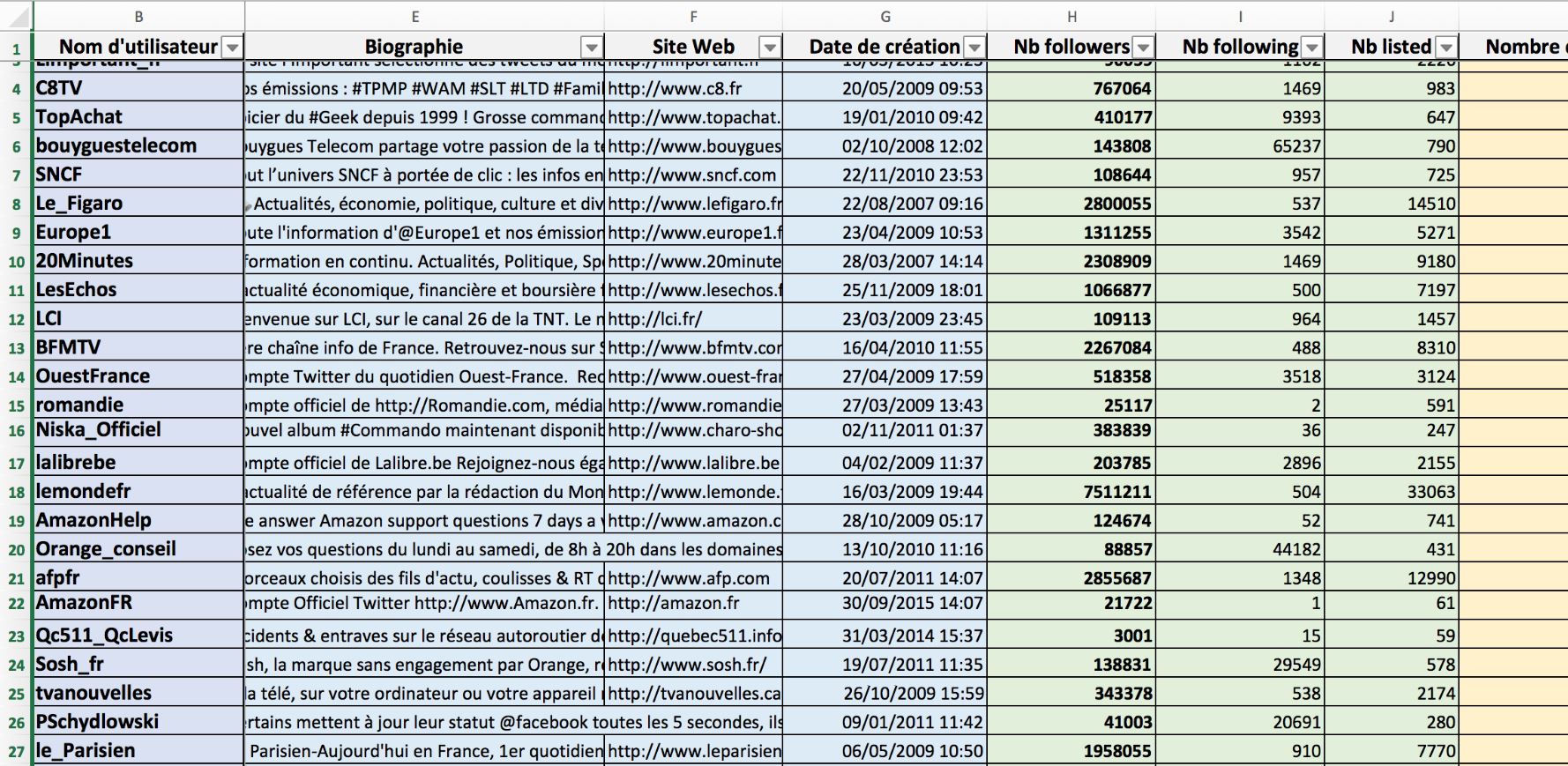
Vous pouvez aussi exporter tous les followers, en les croisant (source) :

Et, si vous le souhaitez (et payez), vous pouvez même avoir accès à l’historique Twitter depuis 2006 (source) !
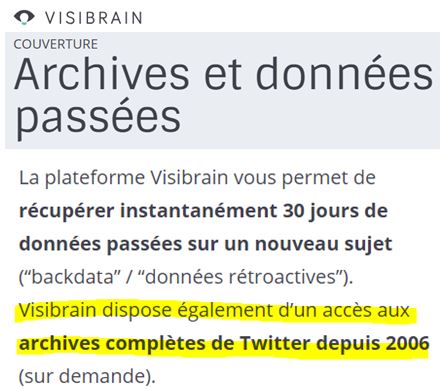
Car bien sûr le logiciel est payant – comptez quelques milliers d’euros par mois pour récolter quelques centaines de milliers de tweets…
Comme vous le savez peut-être, le 25 mai 2018, le règlement européen général sur la protection des données (RGPD) est entré en application pour augmenter la protection des données des citoyens.
Eh bien c’est à peine le 27 juin dernier que Twitter a décidé de donner accès à ses archives à Visibrain (source) :
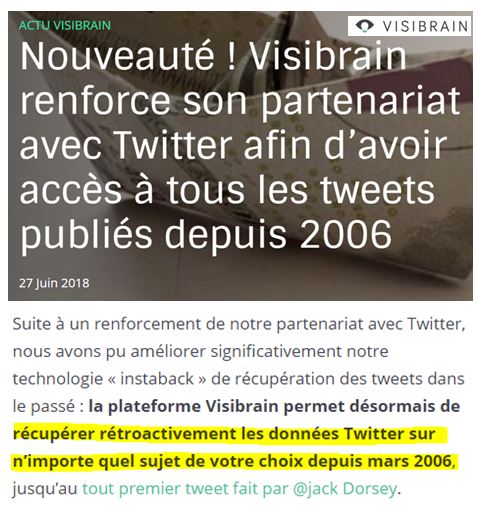
II. Que prévoient les conditions d’utilisation Twitter ?
À ce stade, vous devez commencer à être effrayé de la masse d’informations mise à disposition – et de ce qu’on peut en faire…
Si vous vous demandez ce que prévoit Twitter à ce sujet, voici une sélection des conditions (source {3}) :
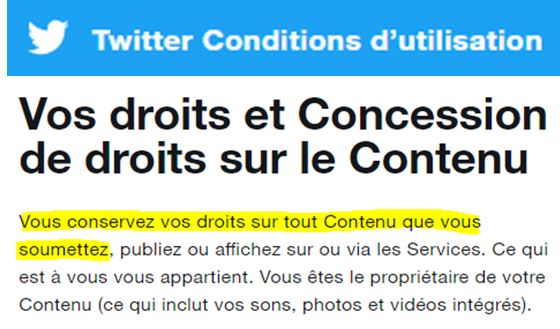
Bonne nouvelle vous conservez vos droits sur tout votre contenu !
Mais bon… :

Twitter et ses clients en font ce qu’ils en veulent et vous ne pouvez vous y opposer !
Car tout est public (source) :
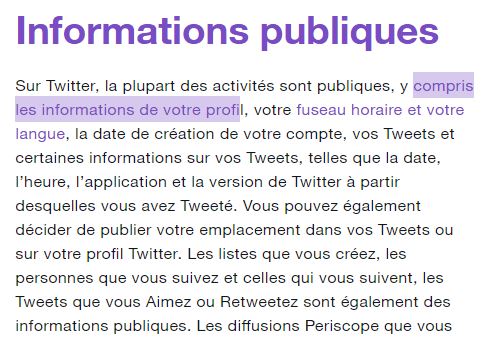
Et donc ils vous conseillent :

Car en plus de l’utilisation du site Twitter :

ils utilisent d’autres interfaces (API) pour diffuser en masse les contenus, moyennant rémunération. C’est le cas avec Visibrain.
Twitter insiste (source) :

d’autant plus que c’est Twitter qui vend l’accès aux API qu’il a développées pour permettre de telles recherches… (source) :


Donc Twitter indique qu’il vend vos contenus, par exemple “aux ONG”, aux “Nations-Unies”, par exemple pour lutter contre le “complotisme anti-vaccins” (dans les pays “à majorité musulmane”) ou lutter contre “les épidémies” telles “la grippe”.
C’est beau…
Bon, ok, dans l’écrasante majorité des cas, ce sera des entreprises telles Boeing pour savoir ce que les twittos disent d’elles (voire des “chercheurs” voulant connaitre vos opinions politiques) – mais on imagine qu’il ne faut pas se plaindre, puisqu’on vous dit que ça permet à des gens de ne pas mourir… Et Twitter est sympa (source) :

Il ne vend pas vos messages privés ! (les messages publics étant bien entendu vendus, eux). Car attention, Twitter a des “valeurs fondamentales” (source) :

Et la “confidentialité” en fait partie. Ils font donc très attention dans leurs “prises de décision” – comme, par exemple, quand ils autorisent Visibrain à accéder à l’historique Twitter depuis 2006… Mais c’était prévu (source) :

En conclusions, certains d’entre vous se diront peut-être : “Mais où le mal, ce sont des données publiques ?”. Eh bien nous illustrons le problème dans la partie suivante…
III. Un laboratoire du CNRS aurait aussi fiché les opinions politiques de près de 200 000 personnes !
Dans le cadre de nos recherches, nous sommes tombés sur cet article des Décodeurs du Monde du 4 décembre 2017 :
Adrien Sénécat nous indique qu’ils ont pu croiser “une dizaine de bases de données sur la période électorale”, lors de l’évènement Datapol :

Ils ont réalisé une première étude sur “les fausses informations” (définies selon les critères méthodologiques du… Décodex). Puis une seconde qu’ils titrent “Les partisans de Marine Le Pen partagent plus de sources peu fiables que les autres” :
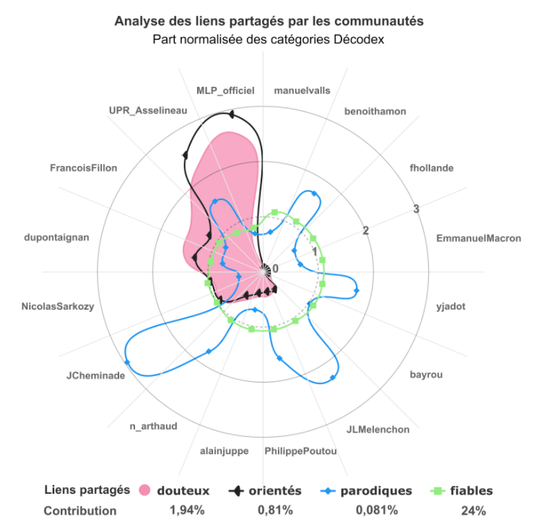
“Un autre enseignement intéressant est apparu en croisant les données du Décodex avec celles du Politoscope. […] À partir de cette typologie et des données anonymisées du Politoscope, les participants à Datapol ont donc pu regarder dans quelle mesure les différentes communautés politiques partagent plus ou moins de liens vers les différents types de sources d’information identifiées dans le Décodex.”
L’infographie du Monde est ainsi construite :
- chaque candidat figure sur une tranche ;
- plus un point est éloigné du 0, plus la communauté proche du candidat correspondant a partagé le type de sources en question :
“Il apparaît ainsi que les partisans de Marine Le Pen et François Asselineau sont ceux qui, en moyenne, ont partagé le plus de liens vers des sources considérées comme peu fiables dans le Décodex. Une analyse qui mériterait d’être affinée par un travail approfondi, mais qui a le mérite d’apporter des données pour accréditer un comportement identifié par de nombreux observateurs pendant la campagne.”
Avant de continuer sur notre axe, signalons quelques interrogations méthodologiques. D’abord, rappelons que la population des personnes inscrites sur Twitter n’est clairement pas représentative de la population générale (avec 49 % de CSP+ chez les 25-49 ans par exemple – source).
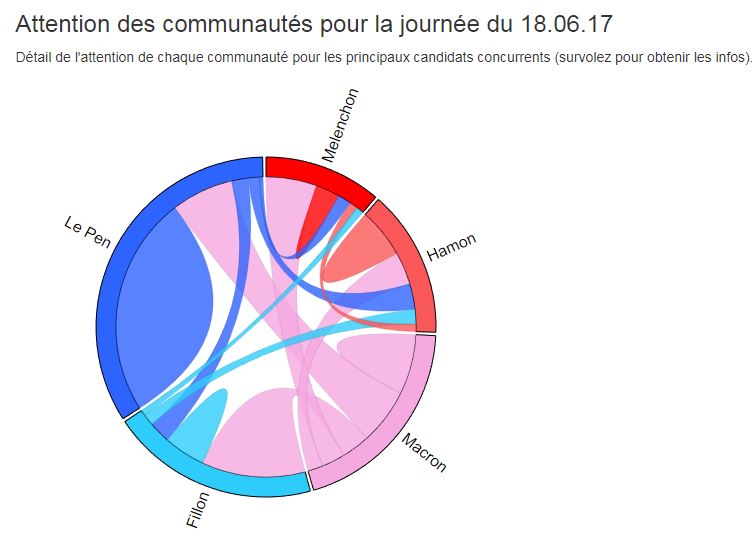
En fait le graphique a utilisé une présentation “douteuse”. On a l’impression en regardant le graphique que les “communautés pro-Le Pen” et “pro-Asselineau” auraient inondé Twitter de liens vers des sites classés “très peu fiables”. Or, les Décodeurs indiquent dans l’article que “lorsqu’un point est proche du cercle de rayon 1, cela veut dire que le type de contenus correspondant a été partagé dans les mêmes proportions que la moyenne. Lorsqu’il est proche du trois, cela veut dire qu’il a été trois fois plus partagé.” Ils représentent donc un simple écart à la moyenne, d’un phénomène marginal, d’où les forts écarts observés, qui sont en fait peu représentatifs. Ceci apparaît en fait clairement quand on observe la courbe verte peu visible de la diffusion de sites “fiables” : il y a assez peu d’écarts entre les candidats en réalité.
Illustrons. Nous avons reconstitué à la main les données du diagramme des Décodeurs. On peut dès lors reconstituer simplement ce que donnerait un graphique plus honnête représentant la diffusion de liens vers les sites classés par le Décodex :
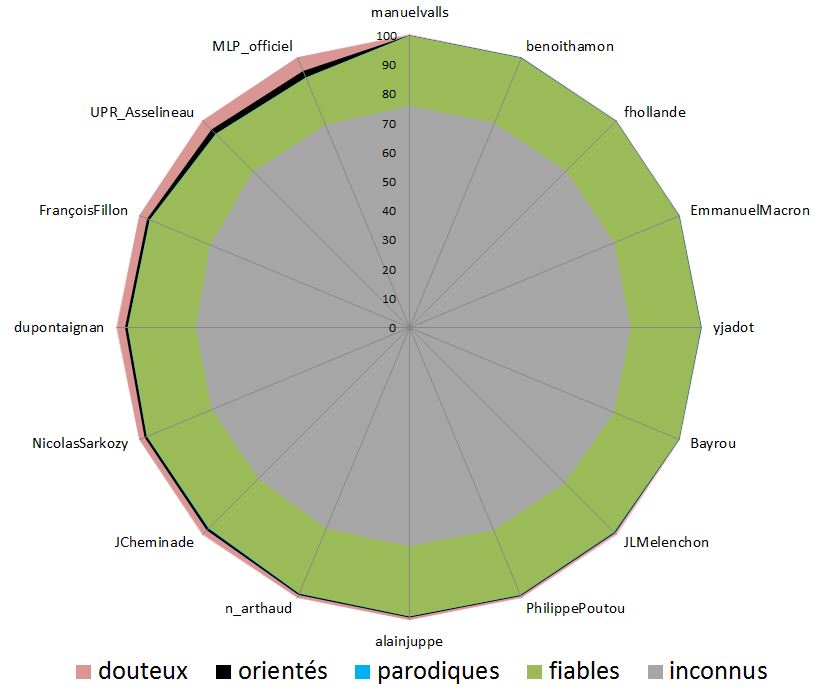
Ce graphique donne donc une impression fort différente au lecteur de l’activité des personnes sur Twitter…
Mais en réalité, le fond de notre problématique est : mais comment savent-ils qui est partisan de qui ?
Revenons donc au Politoscope de L’Institut des Systèmes Complexes Paris-Île-De-France (ISC-PIF, du CNRS). L’article insiste bien : “Dans le cadre de ce projet, l’équipe de l’Institut des systèmes complexes Paris Ile-de-France, un laboratoire du CNRS, a analysé sur la durée de la campagne les messages de milliers d’internautes sur Twitter. L’un des intérêts du Politoscope est qu’il identifie la proximité d’un utilisateur de la plate-forme avec tel candidat au fil du temps”. Voilà ce qu’on trouve sur le site dédié du Politoscope qui explique ceci :


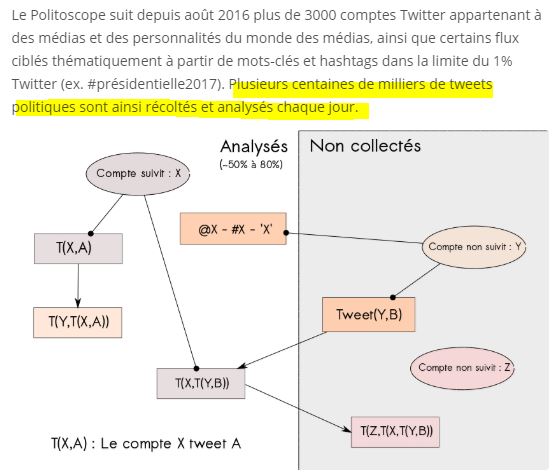

En fait, dans cette étude méthodologique, ils expliquent qu’ils sont partis de 3 700 comptes Twitter de figures politiques françaises, dont ils recueillent ainsi les tweets, mais surtout toutes les informations lors de retweets de ceux-ci ou de réponses (cf schéma précédent):


Et partant de là – vous le voyez venir -, quand l’échantillon de tweets est suffisamment important, ils peuvent (eux-aussi) inclure un compte dans une “communauté politique” :


Et ils font alors des statistiques :
Et on apprend alors (discrètement) combien de comptes ils ont ainsi classé politiquement durant la présidentielle : 187 619 !
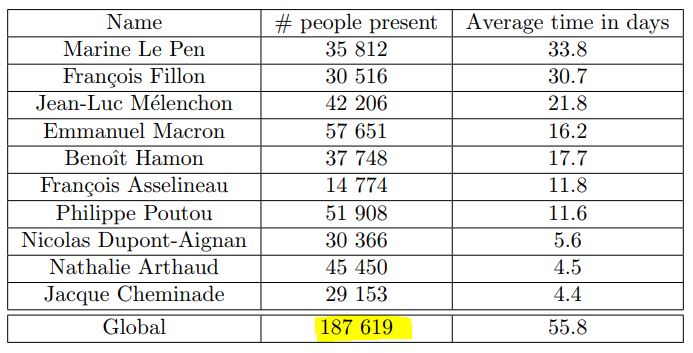
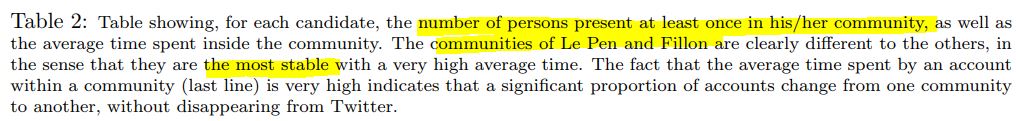
Si on cumule chaque ligne, on arrive à un total 375 000 personnes, car leur méthode est assez frustre (ils n’analysent pas le contenu des tweets par exemple). Ainsi une personne peut-elle est comptée comme pro-Poutou une semaine, puis pro-Arthaud la suivante, puis pro-Mélenchon la suivante, selon ses retweets (car cette sensibilité politique a plusieurs candidats possibles proches). Mais on voit que les auteurs indiquent que les communautés définies comme pro-Le Pen et pro-Fillon sont très stables… (sic.)
Et le plus fort est que leur opération ne s’est pas terminée avec la présidentielle – la base a doublé depuis :

Le Politoscope en est à plus de 126 millions de “tweets politiques”, émanant de plus de 6 millions de comptes Twitter ! (dont une seule fraction est analysée politiquement comme on l’a vu)
L’avantage de ce laboratoire du CNRS, cependant, est qu’ils ne diffusent pas la base publiquement – mais évidemment, la simple existence d’un tel fichier pose de très lourds problèmes – sachant que n’importe quel gros utilisateur de Visibrain (ou de l’API de Twitter directement) peut faire de même, et largement perfectionner les attributions politiques s’il le souhaite…
Après, certains diront que ce sont juste des chercheurs animés de bonnes intentions. Ce qui est vrai.
Mais on répondra : “mais quelle est la réelle valeur ajoutée de ces travaux ?”. Bien sûr on apprend des choses, mais est-ce vraiment si important ? Cela vaut-il le risque que de tels fichiers soient constitués – et donc peut-être utilisés un jour (ou simplement piratés) ? Êtes-vous à l’aise avec le fait qu’un tel fichier existe ?
Big Brother ?
On imagine cependant que le laboratoire aura fait montre de prudence que DisinfoLab.
Mais cela pose néanmoins de nombreuses questions : les données sont-elles anonymisées, comment sont elles-stockées, est-il vraiment impossible de lever l’anonymat si la base était piratée ? (cela semble difficile, car il suffit de retrouver certains tweets dans Twitter, etc.)
Espérons en tout cas que ce laboratoire répondra rapidement à nos interrogations, qui restent à prendre au conditionnel…
IV. Réglementation et Discussion
Rappelons que le Code pénal précise ceci :
Article 226-16
Le fait, y compris par négligence, de procéder ou de faire procéder à des traitements de données à caractère personnel sans qu’aient été respectées les formalités préalables à leur mise en oeuvre prévues par la loi est puni de cinq ans d’emprisonnement et de 300 000 euros d’amende.Article 226-18
Le fait de collecter des données à caractère personnel par un moyen frauduleux, déloyal ou illicite est puni de cinq ans d’emprisonnement et de 300 000 euros d’amende.Art. 226-19
Le fait, hors les cas prévus par la loi, de mettre ou de conserver en mémoire informatisée, sans le consentement exprès de l’intéressé, des données à caractère personnel qui, directement ou indirectement, font apparaître les origines raciales ou ethniques, les opinions politiques, philosophiques ou religieuses, ou les appartenances syndicales des personnes, ou qui sont relatives à la santé ou à l’orientation ou à l’identité sexuelle de celles-ci, est puni de cinq ans d’emprisonnement et de 300 000 € d’amende.Art. 226-22
Le fait, par toute personne qui a recueilli, à l’occasion de leur enregistrement, de leur classement, de leur transmission ou d’une autre forme de traitement, des données à caractère personnel dont la divulgation aurait pour effet de porter atteinte à la considération de l’intéressé ou à l’intimité de sa vie privée, de porter, sans autorisation de l’intéressé, ces données à la connaissance d’un tiers qui n’a pas qualité pour les recevoir est puni de cinq ans d’emprisonnement et de 300 000 € d’amende.La divulgation prévue à l’alinéa précédent est punie de trois ans d’emprisonnement et de 100 000 € d’amende lorsqu’elle a été commise par imprudence ou négligence.
L’article 8 de la loi n°78-17 du 6 janvier 1978 (CNIL) apporte toutefois un bémol :
I. – Il est interdit de traiter des données à caractère personnel qui révèlent la prétendue origine raciale ou l’origine ethnique, les opinions politiques, les convictions religieuses ou philosophiques ou l’appartenance syndicale d’une personne physique ou de traiter des données génétiques, des données biométriques aux fins d’identifier une personne physique de manière unique, des données concernant la santé ou des données concernant la vie sexuelle ou l’orientation sexuelle d’une personne physique.
II. – Dans la mesure où la finalité du traitement l’exige pour certaines catégories de données, ne sont pas soumis à l’interdiction prévue au I :
1° Les traitements pour lesquels la personne concernée a donné son consentement exprès, sauf dans le cas où la loi prévoit que l’interdiction visée au I ne peut être levée par le consentement de la personne concernée ;
4° Les traitements portant sur des données à caractère personnel rendues publiques par la personne concernée ;
Il y a bien sûr deux types de données. Celles publiées par l’utilisateur, et celles déduites par des algorithmes à partir des précédentes.
C’est ainsi que, par exemple, Samuel Laurent a pu dire ceci, interpellé à propos des fichiers DisinfoLab :
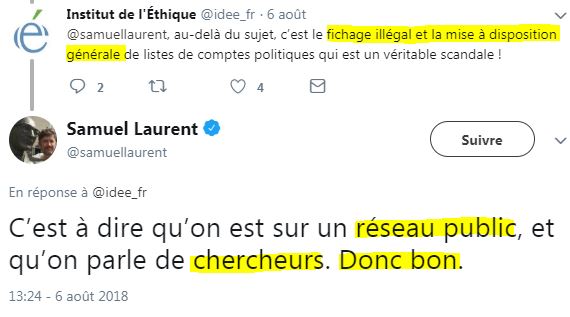
Ce n’est évidemment pas faux – pour la partie publique (et peut-on véritablement parler de “chercheurs” pour des personnes non universitaires ?).
Mais, première objection : quand ce jeune étudiant indique son nom et sa couleur politique, pour agir sur Twitter avec ses… 23 abonnés ;
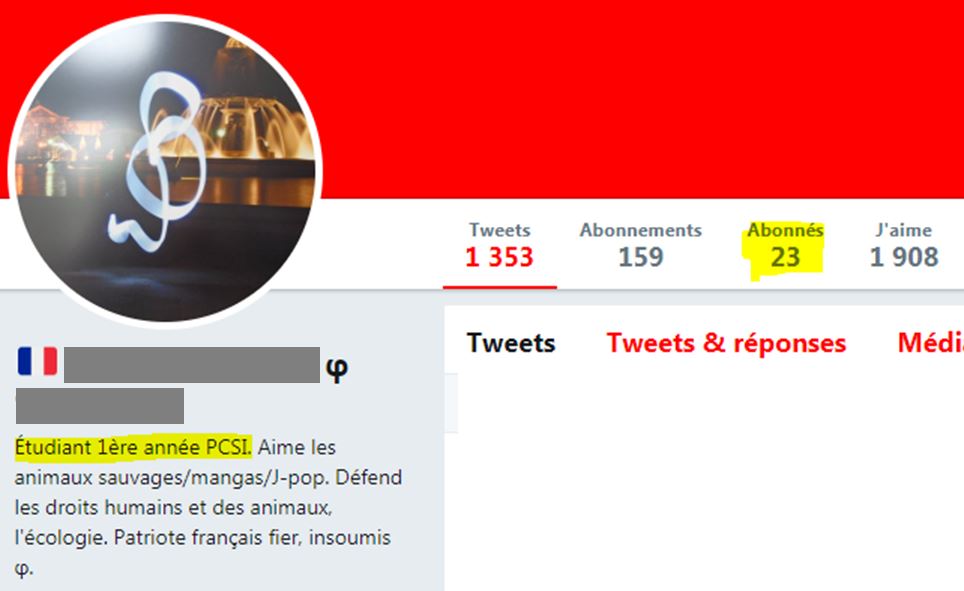
À t-il bien véritablement donné son accord pour que de nombreux analystes créent des fichiers avec son nom et ses opinions politiques ?
Il l’a certes dit publiquement sur Twitter, mais si c’est public, cela reste discret. Et un tweet s’oublie vite dans le fil, et le compte peut s’effacer. Mais ce n’est pas possible si des chercheurs créent des fichiers en permanence, non purgés.
Avec ce raisonnement, on pourrait d’ailleurs ficher plein de personnes : on vous reconnait en train de participer à une manifestation France Insoumise, vous sortez du local Les Républicains, vous avez défendu Macron dans l’affaire Benballa lors d’une discussion au bistro (surtout, ne prenez pas la route !). C’était public – peut-on vous ficher avec vos opinions politiques ?
Et par ailleurs, on peut vraiment se demander si “la finalité du traitement exige” une telle utilisation des données.
Au-delà, il faut bien comprendre que cette notion légale de “données rendues publiques”, acceptable en 1976, ne l’est plus aujourd’hui. En effet, par exemple avec Twitter, il y a différentes façons de connaitre vos opinions politiques :
- vous l’avez dit en dur dans votre biographie ou votre libellé de compte, comme l’étudiant ci-dessus (public) ;
- vous l’avez dit dans un tweet le soir du 1er tour de la présidentielle (public) ;
- vous relayez surtout un dirigeant politique (inférence très probable) ;
- vous parlez en général de vos opinions de nature politique, sans être partisan – “il faut libérer les énergies, on paie trop d’impôts pour trop de fonctionnaires, etc.” (inférence probable)
- vous parlez beaucoup de vous sur Twitter, vous suivez et retwittez beaucoup de personnes. Et c’est là que le Big Data peut inférer vos opinions politiques avec une précision que vous n’imaginez probablement pas. (inférence possible)
Ainsi, désormais, les pouvoirs publics ne doivent pas seulement s’occuper des données non publiques, mais également de la collecte et surtout la diffusion de masses de données publiques, en particulier sur les réseaux sociaux.
Twitter est ainsi gravement fautif – finalement bien plus que DisinfoLab ou le ISC-PIF du CNRS. Après tout, si vous donnez des millions de données à des chercheurs, certains finiront immanquablement par les utiliser ainsi…
Bref c’est bien les conditions d’utilisation de l’API de Twitter qu’il faut viser dans le combat pour la protection des données de la population (source) :

Quand on pense que la CNIL a été créée en 1978 après une vive émotion dans l’opinion publique suite à un projet gouvernemental visant à identifier chaque citoyen par un numéro et interconnecter, via ce numéro, tous les fichiers de l’administration – on se rend compte de l’énorme baisse de notre vigilance, et des risques pour les Libertés publiques…
IV. Plainte
Nicolas Vanderbiest a déclaré :
et :
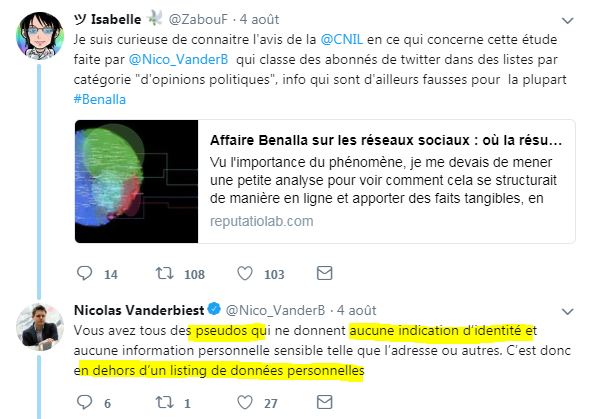
Pour vérifier cela, j’ai porté plainte à la CNIL. – comme beaucoup d’entre vous l’ont fait. Nous soutenons en effet que l’identifiant Twitter (pseudo ou pas) est bien évidemment une donnée personnelle.
J’ai également mandaté mon avocat afin de prévenir le Procureur de la Républiquede ces faits particulièrement graves.
Nous allons évidemment saisir également la CNIL belge et la CNIL irlandaise (siège de Twitter), ainsi que les services Protection des données de la Commission européenne.
Si des gens veulent nous aider pour agir à l’international, ou pour prévenir d’autres utilisateurs concernés et afin de grouper les plaintes, ou si vous êtes spécialiste de ce sujet de protection des données et pouvez nous aider, vous pouvez nous écrire ici.
(Billet édité)




















Commentaire recommandé
Les meilleurs réseaux sociaux, inaccessibles au CNRS comme aux flics d’EU Disinfo Lab : la parole, le regard entre amis, la lettre écrite à la main et cachetée dans une enveloppe.
34 réactions et commentaires
– Soit l’identifiant est privé et la personne est juridiquement responsable des propos publics qu’elle diffuse mais ne peut être commercialisé,
– soit elle est publique et dans ce cas elle ne peut être tenu responsable des propos qu’elle diffuse et tombe dans le commerciabilisable.
C’est je pense un choix que la loi et la société en générale doivent faire mais elle ne peut-être à la fois l’une et l’autre.
Ceci dit ce débat me confirme que les réseaux sociaux doivent être limité à ce que l’on considère comme accessible et le reste ne pas y être diffusé mais certains sont hélas inconscient des risques qu’ils prennent (note pour moi_même éviter Twitter, Instagram,…😱🤔😅)
14
ALERTER
Oui ou procéder de façon anonyme et sous un vpn (faut se protéger).
ALERTER
Les meilleurs réseaux sociaux, inaccessibles au CNRS comme aux flics d’EU Disinfo Lab : la parole, le regard entre amis, la lettre écrite à la main et cachetée dans une enveloppe.
27
ALERTER
Et encore la parole est captée par les micro des stmartphones !
4
ALERTER
Petite faute de frappe avant la cartographie, le “n” et le “b” étant des lettres voisines sur le clavier, c’est Vanderbiest au lieu de Vanderniest. Même erreur dans l’autre article sur Visibrain.
1
ALERTER
Toute cette description de méthodologies, et autres techniques, vise à créer l’illusion qu’il puisse y avoir encore “une opinion”.
Autrement, à quoi peut servir cette débauche de démonstration d’un supposé flicage quand on sait que le néolibéralisme a imposé par ses médias, rien d’autre qu’une vague doxa populiste mollassonne.
“Avoir une opinion” consiste d’abord à le faire savoir, en être fier et la défendre au forum. Qui en est encore capable aujourd’hui?
Que vaut une opinion qui n’est pas “publique”?
3
ALERTER
Pour qu’il y ait doxa populiste il faut qu’il y ait peuple. Hors un objectif du néolibéralisme est de fracturer les peuples pour pouvoir dissoudre les états-nation dans vaste ensemble global.
Pour y arriver ils essaient d’imposer une vague doxa individualiste ou communautaire mollassonne, pas populiste du tout. Les réactions populistes sont juste les saines tentatives des peuples malades du néolibéralisme de reprendre le contrôle.
Après, on peut discuter de la récupération par les uns pour des motifs électoraux, ou par les autres pour des motifs de propagande néolibérale.
14
ALERTER
Non, pour la doxa populiste, il faut de la populace.
Le peuple, c’est en démocratie, la populace c’est en ochlocratie.
C’est justement ces glissements sémantiques, et ces simplifications lexicales qui font le lit du néolibéralisme conformément à leur bible sur la novlangue :1984.
4
ALERTER
Gouvernement où le pouvoir est aux mains de la multitude, la populace. Désordres de l’ochlocratie; dégénérer en ochlocratie. Les gueux attaquent le droit commun; l’ochlocratie s’insurge contre le démos. Ce sont des journées lugubres; car il y a toujours une certaine quantité de droit même dans cette démence, il y a du suicide dans ce duel; et ces mots, qui veulent être des injures, gueux, canaille, ochlocratie, populace, constatent, hélas! plutôt la faute de ceux qui règnent que la faute de ceux qui souffrent (Hugo,Misér.,t.2, 1862, p.407).L’ochlocratie perdit la république d’Athènes, et rendit possible en France le règne de la Terreur (Bach.-Dez.1882).En Allemagne, dès le début de 1790, Schlozer, sans désavouer les principes libéraux, se mit à attaquer l’«ochlocratie», la tourbe démagogique qui dominait en France (Lefebvre,Révol. fr.,1963, p.212).
http://www.cnrtl.fr/definition/ochlocratie
ALERTER
Et bien voila, je pense qu’on l’a plus ou moins vu venir mais c’est bien de pouvoir s’appuyer sur des faits précis. Voila pourquoi je ne veux pas de smartphone, ni de compte sur un réseau asociale.
Benjamin Bayard à bien expliquer comment fonctionne la collecte de masse de l’information avec la complicité active des utilisateurs puisque c’est eux même qui remplissent leur propre fiche en fait…
Pour cela rien de plus “simple”, il suffit de leurs donnés accès gratuitement à des outils et services à la pointe de la technologie. Le premier et le plus pertinent était certainement google (le fait qu’il y ait eu rapidement beaucoup de service de boite mail gratuite sur internet n’est probablement pas non plus anodin), mais la création des réseaux sociaux avec facebook pour centralisé toutes les opinions et tendances des utilisateurs sur des serveurs privés c’est encore plus fort. Le reste est une histoire de profilage systématique par algorithme qui transforme cette masse gigantesque de données en espèces sonnante et trébuchante. Et il est évident que ces outils ont le plus grand intérêt pour les services secret de tous pays.
Il faut remarquer aussi que la surveillance permanente de la population se mue tranquillement en contrôle permanent désormais puisque les gafa censure ouvertement certain contenus et même des “influenceurs”, comme Alex Jones.
Une nouveauté aussi c’est la représentativité des réseaux asociaux dans les médias “traditionnel” (France 24 et France Infaux en particulier). Comme les chroniques ou ont explique après un débat politique, les tendances des commentaires des utilisateurs, quelques fois mêmes avec de joli graphiques comme ceux représenter dans l’article. Les RS pourtant très peu représentatif de la population deviennent une référence d’opinion et de tendance de la population, peut être bientôt au même rang que les fameux sondage.
9
ALERTER
Ça a plutôt bénéficié à Alex Jones + 5 millions d’abonnés. 🙂
Effet Streisand garanti.
Mais bon sang les enfants, VOUS avez encore votre volonté! VOUS pouvez!
Get out of the groove – Sortez du cadre! Sortez des règles! Et je ne tombe même pas sous le coup de la Loi puisque c’est du Président Macron dans le texte, s’adressant à des étudiants indiens…
Les types en face sont exactement comme vous et avec les mêmes moyens! Pas des Superman extraterrestres.
M’enfin..!
La technologie n’est rien sans les humains et “5” humains tous seuls ne peuvent pas tout contrôler…
2
ALERTER
Même l’API de twitter et le fait d’avoir mentionné son opinion politique ou ses préférences sexuelles dans les données “publiques” de twitter ne permet pas à mon avis le traitement de ces données tel qu’il a été effectué par UE DisinfoLab.
L’article 7.2 du RGPD (Conditions applicables au consentement) rappelle en effet en ses 2. et 3. que :
“2. Si le consentement de la personne concernée est donné dans le cadre d’une déclaration écrite qui concerne également d’autres questions, la demande de consentement est présentée sous une forme qui la distingue clairement de ces autres questions, sous une forme compréhensible et aisément accessible, et formulée en des termes clairs et simples. Aucune partie de cette déclaration qui constitue une violation du présent règlement n’est contraignante.
3. La personne concernée a le droit de retirer son consentement à tout moment. Le retrait du consentement ne compromet pas la licéité du traitement fondé sur le consentement effectué avant ce retrait. La personne concernée en est informée avant de donner son consentement. Il est aussi simple de retirer que de donner son consentement (…)”.
Quid du consentement discinct ?
Quid du droit au retrait ?
Quid de l’autorisation pour une finalité spécifique ? ou de son caractère nécessaire ? (art 6)
1
ALERTER
Il va de soi que, même parfaitement conscient de mon imprudence, si j’utilise un réseau social présenté comme tel, avec tout ce que cela suppose de convivialité, et que j’expose mes humeurs politiques, mes goûts musicaux, mes préférences sexuelles et toutes ces sortes de choses, comme dans la vie de tous les jours on parle de soi à des rencontres de bistrot ou à des potes — il va de soi que j’entends informer sur ma personne les utilisateurs du réseau, des gens comme moi, de futures connaissances, des gens avec qui j’espère des interactions enrichissantes et des affinités dans différents domaines, et en aucun cas des entreprises avides, des statisticiens louches, des tripatouilleurs de data et autres margoulins associatifs déguisés en ONG de bonne famille. Le bon sens incite à la prudence, certes, mais le client usuel qui utilise un réseau social ne peut décemment s’attendre à ce que tout ce qu’il publie puisse être conservé à travers les siècles et les continents, faire l’objet d’études pour le moins suspectes parfois, comme ici. On peut trouver les gens naïfs, mais il me semble qu’une société reposant sur le soupçon permanent et sur la crainte soit infiniment moins aimable, moins enviable qu’une société normale, c-à-d plutôt basée sur une relative confiance en autrui.
1
ALERTER
Merci encore a OB pour ces articles illustratifs qui mettent bien les points sur les i a ceux qui n’avaient pas compris le danger ou les possibilites lies aux analyses des”big data”.
apres je reste convaincu que cette analyse des donnees reste un outil qui peut etre utile ( attention,d’apres l’analyse des banques de donnees liees a votre region,vous avez 22,4% plus de chance d’avoir une leucemie du fait de votre proximite de l’usine machin) ou etre un moyen d’oppression. tout comme une arme a feu par ex.
1
ALERTER
Et oui, ils savent absolument tout de nous, et peuvent même prédire nos comportement d’achat à l’avance. Moi, je n’utilise plus mon téléphone portable, mais encore trop Internet. J’avais déjà jeté mon téléviseur, je crois que je vais aussi jeter tout ça bientôt…
3
ALERTER
Continue d’utiliser ton |téléphone| (c’est utile) et change de comportement. Devient imprévisible. 🙂
ALERTER
Wünderwar!!!! Kolossal!!!! super tout ça, il ne nous manque plus qu’un Reinhard Heydrich assisté d’une armée de Klaus Barbie et c’est l’apothéose.
Et l’Histoire nous a appris qu’en tous temps, en tous lieux, il y a des Heydrich et des Barbie qui n’attendent que l’occasion de se révéler leur vocation.
Avec des trucs comme ça, ils auraient assurément assassiné l’intégralité des juifs d’Europe, la totalité des résistants et possibles résistants, la totalité des communistes, socialistes, libre-penseurs.
En Chine, c’est déjà Minority Report sur algorithme, Face book public obligatoire avec notation par les voisins, collègues, patrons et même passants par la reconnaissance faciale. Minority Report et Black Mirror.
Super le contre-modèle sociétal qu’ils nous proposent les Chinois. Bientôt près de chez vous.
5
ALERTER
Merci au site Les Crises de nous informer sur l’utilisation des données numériques de masse à des fins de fichage politique ou autre. C’est assez technique mais ça vaut la peine de s’y coller.
Nous laissons de plus en plus de traces numériques qui peuvent être exploitées a des fins utiles (criminologie par exemple) mais aussi à des fins liberticides. Ce n’est qu’un début et nous allons vite être submergés d’analyses de données plus ou moins valides sur le plan méthodologique et scientifique. C’est une mine d’or pour des études d’opinion, d’influence mais aussi de marketing social. ça va remplacer les sondages avec encore plus de biais et surtout ça va permettre d’être beaucoup plus intrusif dans la vie privé jusqu’au fichage des individus.
Il faut s’y opposer ou au moins fixer un cadre déontologique.
Remarque: le CNRS n’a pas que des chercheurs bien intentionnés et indépendants du pouvoir. On l’a bien vu avec le nuage de Tchernobyl.
5
ALERTER
Vous écrivez : “Comme vous le savez peut-être, le 25 mai 2018, le règlement européen général sur la protection des données (RGPD) est entré en application pour augmenter la protection des données des citoyens.”
Je pense que vous n’avez pas lu RGPD… En effet, lorsque je lis ce règlement j’y vois le contraire de la protection des données, j’y vois un outil pour facilité la libre circulation de ces données, c’est à dire exactement la revente de nos données par twitter.
Rien que l’article 1 du RGPD, phrase 3 résume cela : “La libre circulation des données à caractère personnel au sein de l’Union n’est ni limitée ni interdite pour des motifs liés à la protection des personnes physiques à l’égard du traitement des données à caractère personnel.”
Mais RGPD est explicite à de nombreuses reprise sur le sujet.
1
ALERTER
Personnellement je m’interroge. Je salue ici bien sûr le travail d’Olivier (et je te salue par la même occasion ;)), et il n’est absolument pas question de remettre en cause ce travail, qui est bien sûr salutaire, dans un pays qui part de plus en plus à la dérive…
Mais, car il y a un mais, est-ce que l’impact de Twitter est suffisant ? Est-ce que la manipulation des données de ce réseau social a un réel impact, hors de sa sphère d’influence, que je trouve en fait très limitée ?
Je sais bien que la guerre se mène sur tous les fronts, et que le principe même de ce fichage est très inquiétant. C’est donc fondamental de le dénoncer… mais sincèrement, est-ce que ça n’a pas une portée très limitée ? Combien de gens qui réfléchissent, utilisent Twitter ? Et combien de gens qui ne réfléchissent pas, l’utilisent également ? (sous entendu =se font manipuler à travers lui ?). Peut-être que j’extrapole, ou que je parais même pédant, mais où est l’intérêt d’un réseau social qui permet de débattre, polémiquer, argumenter… Tout ça en 240 caractères ?
En gros… Quelle est la réelle influence de Twitter ?
1
ALERTER
On parle de 6 millions de comptes twitter, soit 10% des français… Cela commence à être conséquent.
De plus, c’est la même chose avec Facebook, ou tous les autres réseaux sociaux.
C’est le principe qui est en cause, de l’utilisation de nos données pour nous ficher/contrôler politiquement. Une fois les plus gros influenceurs connus, on peut le censurer sans même qu’ils ne s’en rendent compte. On peut donc étouffer dans l’œuf les oppositions. Reste comme ici les sites indépendants, qu’il faut réduire au silence avec le Decodex.
2
ALERTER
Très intéressante réflexion. Merci.
Cependant, je constate avec regret que la presse (et les gouvernements) sont branchés sur les tweets de Trump….
Pathétiques, capables de déclancher des cataclysmes …
Il faut donc en tenir compte, de Tweeter.
2
ALERTER
ce que cet article illustre a propos de twitter peut etre etendu a tous les reseaux sociaux. pire a tout ce qui passe par internet.
ce qui veut dire grosso modo que le ministere de l’interieur,la police, les espion, le “deep state” de chaque pays ” avancé” :
-sait a quels sites internet vous vous connectez
-en deduit vos convictions politiques,religieuses,sexuelles
-stocke toussa dans des fichiers
-en deduit des comportements futurs, des previsions de resultats d’elections, des necessites d’action pour influencer dans le sens voulu.
quelque part ca pourrait etre de la democratie participative directe,si les citoyens sont assez ” malins” pour ne pas se laisser trop influencer par le “top down”.
par ce que quelque part,ce “fichage” c’est comme si l’”etat” savait tout ce que la “majorite” veut.Pour se faire reelire,le pouvoir n’a qu’a le realiser,c’est le principe de la democratie en theorie.dans la pratique,le pouvoir aliene le peuple et lui fait desirer ce qui est bon pour l’elite et non pas ce qui est bon pour le “peuple”.
cette histoire est une enieme resurgence technologique de la lutte du “bottom up” contre le “top down”.
etes vous “actif” et vous battez vous pour realiser vos propres desirs ou etes vous “passif” et vous laissez vous imposer la volonte d’un autre?
1
ALERTER
La “qualité” des twittos est sans aucune mesure avec la quantité des utilisateurs. Regardez l’influence d’un simple tweet de Trump. Les tweets sont devenus un morceau de choix pour les journalistes : plus besoin de se déplacer, l’info va directement à eux.
Certains articles de journaux ne reposant que sur des captures d’écran de Twitter (tweets d’hommes politiques, d’artistes, d’ONG, de simples citoyens…), son impact est largement supérieur au nombre minime de ses d’utilisateurs (par rapport par exemple aux personnes qui regardent les journaux télévisés ou radiophoniques).
Les tweets et retweets sont également une bonne mesure de buzz, ce qui contribue à faire entrer dans le monde médiatique traditionnel les infos qui y sont partagées.
C’est donc indirectement que son influence est très réelle. Si les tweets ne sortaient pas de Twitter, effectivement, leur influence serait nulle.
3
ALERTER
« En gros… Quelle est la réelle influence de Twitter ? »
Facebook, Twitter, et tout semblable tra-la-la. — Il suffit pourtant de tout simplement refuser, de nous détourner, de laisser tomber, d’abandonner… et toute influence cesse d’exister. Il y eut vie humaine, et riche de sens, avant le big tra-la-la. Le choix demeure, aujourd’hui encore, entièrement nôtre.
Devant Zénon niant le mouvement, sans un mot, Diogène lui tourna le dos, mit un pied devant l’autre… et s’éloigna.
1
ALERTER
Au fait, dans la lignée :
Pour les défi du defcon, ils ont décidé de laisser aux enfants le soin de hacker une machine de vote, parce qu’ils considèrent que c’est beaucoup trop facile pour un adulte.
ALERTER
« Dès que le plus faible des hommes a compris qu’il peut garder son pouvoir de juger, tout pouvoir extérieur tombe devant celui-là… si les gardes refusent de croire, il n’y a plus de tyran… Commence par toi-même… ta propre faiblesse, tu la renvoies au maître comme un attribut de force; c’est ta propre lâcheté… qui en lui te fait peur; et cette peur tu veux la nommer respect. Qui que tu sois, tu fais partie de la garde; ce mercenaire qui est toi- même… qu’il découvre cette vérité étonnante et simple, c’est que nul au monde n’a puissance sur le jugement intérieur; c’est que, si l’on peut te forcer à dire en plein jour qu’il fait nuit, nulle puissance ne peut te forcer à le penser. Par cette seule remarque la révolte est dans la garde, la vraie révolte; la seule efficace… Avant d’apprendre à dire non, il faut apprendre à penser non. »
( Alain, « Propos** », Pléiade, 352, p. 539 sq.)
1
ALERTER
Merci de ne pas mélanger le CNRS, qui est une des nombreuses tutelles parmi d’autres de milliers de labo en France, avec un laboratoire de recherche en lui-même. Les chercheurs et les personnels techniques sont libres d’orienter leurs travaux comme ils le souhaitent. Si cela contrevient à des principes d’éthiques, vous pouvez en effet contacter le CNRS (qui je crois possède des garde fou à ce niveau là), mais je vous conseille plutôt de contacter les laboratoires en premier. Enfin, et même si je le regrette parfois, le but premier des chercheurs en recherche publique est l’élargissement des connaissances, quelque soit “la valeur ajoutée” des connaissances générées. Parler de valeur ajoutée est à mon sens absurde car elle est à l’appréciation du chercheur, et ce terme se rapproche trop de la recherche privée qui n’a pas le même objectif.
ALERTER
ligne de fuite : pratiquer la déconnexion, doublée d’obfuscation permanente, de façon à mettre les algos en état de panique cognitive
ALERTER
Il abuse Olivier, quel mauvais travail documentaire :p (je taquine avec gentillesse).
http://www.lefigaro.fr/secteur/high-tech/2018/08/10/32001-20180810ARTFIG00178-donnees-personnelles-l-ufc-que-choisir-fait-plier-twitter.php
Il faut citer l’initiative de l’UFC-Que Choisir, sinon l’article est incomplet car ils ont bien avancé sur le sujet Twitter.
ALERTER
Avec RGPD, la protection des données n’est peut-être plus vraiment assuré… Depuis le 25 mai dernier, les grandes entreprise ont le droits de faire ce qu’elle faisaient déjà : https://youtu.be/FbD4pEjuCKE
ALERTER
vaste débat…. d’un coté de l’atlantique l’Amérique devient leader en IA par exploration massive des données personnelles, de l’autre on s’insurge contre le fichage des citoyens par le CRNS…
Scandaleux ou pas le 21eme siècle est comme ça. On y est tous fiché. Dénoncer un scandale ne changera pas le fait qu’on a vendu notre âme a google face book et twiter et à visa mastercard avant eux. Le fichage existe et il faut faire avec, Rester prudent dans les informations qu’on laisse évidentes, devrai être une règle d’hygiène numérique enseignée à l’école. Le recoupement des données et l’IA est d’autant plus facile si tout est déja laissé volontairement dans son profil pour y revendiquer une appartenance à une communauté.
On reproche à des organismes d’exploiter les données des GAFA en constituant des “fichiers”, mais ces “fichiers” sortent de fichiers créer volontairement avec amour et patience pour afficher son profil au monde (qui n’en avait rien a faire).
ALERTER
« Mais, première objection : quand ce jeune étudiant indique son nom et sa couleur politique, pour agir sur Twitter avec ses… 23 abonnés «
En l’occurence le CNRS a analysé les twitts publics c’est-à-dire ceux publiés en dehors du cercle d’abonnés (en réponse ou en RT d’une personnalité qui publie en public).
De ce que j’ai vu on peut choisir si ses twitts sont limités à son cercle (followers qu’on a accepté, ou non si on est un personnage public qui autorise n’importe qui de le suivre). Donc quand on commente l’activité de ce type de personne on rentre dans son cercle public et donc on n’est plus avec uniquement ses 23 abonnés.
Je ne sais pas si l’analyse est juste car je n’utilise pas Twitter mais je trouve que ça met un bémol sur l’argument de dire qu’un utilisateur ayant 23 abonnés ne pense pas publier des infos au-delà de son cercle.
ALERTER
Sur Internet, on a le choix du pseudonyme (c’est donc un choix de mettre sa vrai identité – en tout cas affiché aux yeux de tous.)
Ce n’est absolument pas une données personelle. Si vous ne connaissez pas l’histoire d’Internet, laissez-le aux cryptoanarchistes ou rejoignez les dans leur combat.
Vous avancez a tatillon, malgré de bon raisonnement (Les GAFAM et leur système de recommandations, de publicités et d’orientation de l’information font la même chose, en cachés, sans que vous n’en ayez pris connaissance – et qui est à mon sens beaucoup plus grave que le politoscope, que vous pouvez tout à fait recrez chez vous en recoltant des tweets, une fois apres avoir appris la méthode – que tout le monde peut faire, si tant est que l’on fait l’effort d’apprendre )
ALERTER